Chap 4. Built-in Functions
Contents
- Basic built-in functions, such as type-related functions
- Built-in functions that handle strings, regular expressions, and globs
- Built-in HTTP and JWT functions for external system interworking
OPA provides a variety of predefined built-in functions. OPA supports a variety of built-in functions needed to implement policies, such as encoding and JWT token processing, as well as built-in functions for basic functions such as type checking, strings, and regular expressions.
This chapter mainly describes the various built-in functions of OPA that are often used in policy writing. We also use the grammar in the previous chapter to write functions that are frequently used but not provided by OPA. However, the operators that OPA also describes as built-in functions are omitted if already described in Chapter 3.
Figure 4-1. OPA built-in function reference
For referencing built-in functions, see https://www.openpolicyagent.org/docs/latest/policy-reference/#built-in-function on the OPA official homepage, as shown in Figure 4-1.
If the function described in the reference does not work, let's update the OPA version to the latest one. In other programming languages, built-in functions are documented from which version they are supported, but OPA does not provide information about which version they are supported. For example, the number.range() function is not supported in the version 0.19.x, the OPA version at the time this book was started, but it is supported in the latest version. These documentation details are a bit of a bummer for OPA.
Number Related Functions
Round, Floor, Ceil
OPA provides a rounding function named round. The round function returns a rounded value by receiving one numeric argument as follows.
# 4
round(4.3)
# 11
round(10.9)
# 3
round(3)
Although previously not provided by OPA, the function "floor" and "ceil" is available in version 0.26.0, which was released in January 2021. Below 0.25.x, the error occurs as follows.
$ opa run
OPA 0.25.2 (commit 4c6e524, built at 2020-12-08T16:57:20Z)
Run 'help' to see a list of commands and check for updates.
> floor(1.2)
1 error occurred: 1:1: rego_type_error: undefined function floor
>
In versions 0.26.0 and above, floor and ceil functions are included.
$ opa run
OPA 0.26.0 (commit 62d3900, built at 2021-01-20T18:56:12Z)
Run 'help' to see a list of commands and check for updates.
> floor(1.2)
1
If the OPA version of used cannot be changed, or if OPA versions below 0.25.x must be used, the floor or the ceil function are not provided, and should be defined directly if necessary.
Let's define a floor function. The name of the function is floornew so that it does not conflict with the floor function of version 0.26.0 or higher. Since the rule body cannot write if or switch statement like other generic programming language, the two rule bodies are linked with an else statement as follows
floornew(num) = round(num) { round(num) <= num } else = (round(num) - 1)
Running the floornew function yields the following integer values:
# 4
floornew(4.3)
# 10
floornew(10.9)
# 3
floornew(3)
Similarly, the ceil function can be defined as:
ceilnew(num) = round(num) { round(num) >= num } else = (round(num) + 1)
Absolute Value
The abs function allows the absolute value of a number.
# 10.4
abs(-10.4)
# 3
abs(3)
Create an array of integers in a specific range
The numbers.range function produces an array of integers in the specified range. Typical range of similar functions has scope from first number to last number - 1. However, numbers.range produces an array containing both the preceding and the latter digits. Also, if the preceding number is greater than the latter, an array is created in reverse order from the preceding to the latter. Because the Rego language used by OPA does not have a direct for loop, the use of numbers.range to create an integer array can similarly implement the for loop.
# [9, 8, 7, 6, 5, 4, 3, 2, 1]
numbers.range(9, 1)
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
numbers.range(1, 9)
Bit Manipulation
OPA supports bit manipulation functions as built-in functions rather than operators. The functions associated with bit operations provided are shown in Table 4-1.
| Function | Description |
|---|---|
| bits.or(x, y) | Calculate the bit OR of the two arguments |
| bits.and(x, y) | Calculate the bit AND of the two arguments |
| bits.negate(x) | Flip the bit. When called for integer arguments, return 2’s complement |
| bits.xor(x, y) | Calculate the bit XOR of the two arguments |
| bits.lsh(x, s) | Shift x to the left by s |
| bits.rsh(x, s) | Shift x to the right by s |
Table 4-1. Built-in Bit Manipulation Functions provided by OPA.
Type-Related Functions
Type Name
By using the type_name function, the type of variable passed as an argument can be obtained. Because type_name returns the result of a string type, type names can be easily compared using the == operator and etc.
An example of a function type_name is shown below. In the case of a composite value such as an array or set, the type is only known as "set", "array", and so on, so in order to know the specific type, the component of the composite value must be referenced and checked again.
# "number"
type_name(3.14)
# "array"
type_name(["apple","banana","pineaplle"])
# "set"
type_name({"apple","banana","pineaplle"})
# "object"
type_name({"weight":80, "height":180})
# “boolean”
default allowed = true
type_name(allowed)
# undefined
alwayswrong = { 1 == 2 }
type_name(alwayswrong)
Invoking the type_name function for a rule returns the type for the evaluated result value of the rule. If the rule is not evaluated and the result is undefined, it becomes undefined.
However, the function type_name cannot use the function itself as a target. An error occurs in REPL when the following code is entered.
func(a) = r { r := a + 1}
type_name(func)
2 errors occurred:
1:11: rego_type_error: undefined ref: data.repl.func
data.repl.func
^^^^^^^^^^^^^^
have: number => number
1:1: rego_type_error: type_name: invalid argument(s)
have: (number => number)
want: (any<any>, string)
If you look at the contents of the error, you can see that type_name cannot be executed for the function. However, if the function is called and the resulting value is assigned to a variable, the resulting value will have a scalar value or complex value, so type_name for the variable containing the resulting value can be called.
# "number"
type_name(func(3))
Type Checking Functions
OPA provides built-in functions in the form is_
| Function | Description |
|---|---|
| is_number(x) | Examine whether x is a numeric type |
| is_string(x) | Examine whether x is a string type |
| is_boolean(x) | Examine whether x is a boolean type |
| is_array(x) | Examine whether x is an array type |
| is_set(x) | Examine whether x is a set type |
| is_object(x) | Examine whether x is a objecttype |
| is_null(x) | Examine whether x is null |
Table 4-2. Type Checking Built-in Functions Provided by OPA.
An example of the use of type-check functions is as follows. Note that it returns undefined rather than false if it is not of that type.
# undefined
is_null(1)
# true
is_null(null)
# undefined
is_set({})
# true
is_set(set())
# true
is_object({})
# true
is_set({1,2,3})
# true
is_string("hello")
Type Conversion Functions
The only type conversion function OPA currently supports is to_number. To_number returns 0 for a null or false and returns 1 for a true. If a string factor is passed, it returns the numerical value that the string represents. For example, if "123" is passed, it returns to 123. If the number type is passed, it is returned without being converted. An error occurs when a string is passed, not a numeric representation, and values other than the defined value are returned undefined.
# 0
to_number(null)
# 0
to_number(false)
# undefined
to_number("abc")
# 1234.45
to_number(1234.45)
#1234.45
to_number("1234.45")
Aggregation Function
An aggregation function of an OPA performs an aggregate operation on an array or set. Among aggregation functions, only counts receive strings or objects as an argument, while other aggregation functions can only use sets or arrays as an argument. Note that in OPA, strings are not an array of characters.
Note again that in OPA, {} represents an object with no
count
The count function can be used for strings, objects, sets, and arrays. When used for a string, it returns the length of the string, and when used for an object, it returns the number of
Examples of use of the count function are as follows. count({}) returned 0 because {} is an object with a zero number of
# 2
count({"width":1024, "height":768})
# 12
count("hello woirld")
# 0
count([])
# 0
count({})
# 0
count(set()})
# 3
count({1,2,3})
sum, product, max and min
The sum, product, max, and min functions return the total sum, total product, maximum value, and minimum value of each element in an array or set taken over by an argument. An example of the use of each function is as follows:
# -0.5
sum({1, 0.5, -2})
# -105
product([1, 3, -5, 7])
# -1
min({-1, 0, 1})
# 3000.11
max( {10, 100, 3000.11 } )
Note that if you run each function on an empty set or array, sum returns 0, product returns 1, min and max undefined, as follows.
# 0
sum(set())
# 1
product([])
# undefined
min(set())
# undefined
max([])
all, any
The all function and any function return whether the elements in the array or set are all true or at least one true, respectively. Thus, if the resulting values of the associated rules are checked by all or any in a set or array, all rules can be checked for whether all or any rule is satisfied.
Before looking at examples of the use of all or any, we define rules that are always judged to be true, always false, and undefined, respectively:
# It's always true.
alwaystrue = true { true }
# It's always false.
alwaysfalse = false { true }
# A rule that would be undefined if the default value was not declared, but it did not declare default.
maybeundefined { false }
An example of the use of all or any of the above rules is shown below. all returns true if the target array or set is all true or empty; any returns true only if any of the target arrays or sets contains true; and false if empty. Also, if an array or set contains undefined, all or any will be undefined.
# true
all([alwaystrue, alwaystrue])
# false
all([alwaystrue, alwaysfalse])
# false
all([true, 1])
# true
any([alwaystrue, alwaysfalse])
# false
any([alwaysfalse, alwaysfalse])
# undefined
all([alwaystrue, maybeundefined])
# undefined
any([alwaystrue, maybeundefined])
# true
all([])
# false
any([])
Composite Value Related Functions
Array related functions
OPA provides functions that manipulatest arrays as shown in Table 4-3.
| Function | Description |
|---|---|
| array.concat(array1, array2) | Returns the array that concatenates the two arrays that are passed to the arguments |
| array.slice(array, startIndex, stopIndex) | Returns an array containing components ranging from startIndex to stopIndex(exclusive) |
Table 4-3. Array manipulation built-in functions provided by OPA.
An example of the use of array related functions is as follows.
# [1,2,3,4,5,4,5,6]
array.concat([1,2,3,4,5],[4,5,6])
# [0, 1, 2]
array.slice([0,1,2,3,4,5], 0, 3)
# [“c”]
array.slice(["a","b","c","d","e"], 2, 3)
Set related Functions
OPA provides intersection and union functions for the set in addition to the infix operators &(intersection), |(aggregation), and -(subset). The intersection function represents the intersection, and the union function represents the union, which, unlike the infix operator, is also possible to obtain the intersection and union for multiple sets at a time.
Note that the sets to be passed to an intersection or union as arguments must be regrouped before passed. For example, to obtain a combination of {1,2} and {3,4}, you must call intersection { {1,2}, {3,4} } instead of intersection ( {1,2}, {3,4} ).
# { 1, 3, 2, 4, 5, 6 }
union({ {1,3}, {2,4}, {5,6} })
# { 1 }
intersection({ {1,2}, {1,3}, {1,4}, {1,6} })
# { 1, 2, 3, 4, 6 }
union({ {1,2}, {1,3}, {1,4}, {1,6} })
Object related Functions
OPA provides a variety of functions to manipulate objects.
object.get
object.get has the form object.get(object, key, default) and returns the value with that key in the object.If there is no value (i.e., an object does not have a value for that key), it returns the value specified by default. An example of the use of object,get is as follows.
obj := {"key1":"val1", "key2":"val2"}
# “val1”
object.get(obj, "key1", null)
# “val3”
object.get(obj, "key3", "val3")
Reference using [] or . will result in an error if the key does not exist in the object as follows. Although object.get always has to set a default value, there is a difference that no error occurs even if the key does not exist.
> obj[“key3”]
1 error occurred: 1:1: rego_type_error: undefined ref: data.repl.obj.key3
data.repl.obj.key3
^
have: "key3"
want (one of): ["key1" "key2"]
> obj.key3
1 error occurred: 1:1: rego_type_error: undefined ref: data.repl.obj.key3
data.repl.obj.key3
^
have: "key3"
want (one of): ["key1" "key2"]
object.remove
object.remove takes the form of object.remove(object, keys) and returns a new object that excludes keys and values corresponding to specific keys from the object. The keys argument has the form of a set or array. An example of using object.remove is as follows.
obj := {"name":"bob", "password":"1234", "role":"admin", "point":1000}
# { "name": "bob", "point": 1000 }
object.remove(obj, ["password","role"])
object.union
object.union has the form object.union(objectA, objectB) and combines the two objects to return a new object. If two objects have values for the same key, they are updated to the value of the second object.
# { "a": "c", "x": { "k": "v", "x": 0 } }
object.union({"a":"b", "x":{"k":"v","x":0}},{"a":"c"})
object.filter
object.filter has the form object.filter(object, keys) and returns a new object containing only values corresponding to that key, as opposed to object.remove excluding values for the specified key
obj := {"name":"bob", "password":"1234", "role":"admin", "point":1000}
# { "password": "1234", "role": "admin" }
object.filter(obj, ["password","role"])
json.filter
json.filter has the form of json.filter(object,paths), which behaves similarly to object.filter, but can also be specified as a path, not as a top-level key. An example of the use of json.filter is as follows..
obj := {"a":{"x":100, "y":200}, "b":{"x":400,"y":300}}
# { "a": { "x": 100 }, "b": { "x": 400, "y": 300 } }
json.filter(obj, ["a/x", "b"])
json.remove
json.remove has the form of json.remove(object,paths), which behaves similarly to object.remove, but also has a non-top key specified as a path. An example of the use of json.remove is as follows.
obj := {"a":{"x":100, "y":200}, "b":{"x":400,"y":300}}
# { "a": { "y": 200 } }
json.remove(obj, ["a/x", "b"])
String related Functions
String Test Functions
contains
contains has the form of contains(string, search) and returns true if the string to be searched is included in the target string and false if not included.
# true
contains("Hello, world", "Hello")
# false
contains("Hello, world", "hello")
indexof
indexof has the form indexof (string, search), returns the index of the starting point where the string to be searched appears in the target string, and returns –1 if the string to be searched is not included in the target string.
# 0
indexof("Hello, world", "Hello")
# -1
indexof("Hello, world", "hello")
# 7
indexof("Hello, world", "world")
startswith, endswith
startwith and endwith have the form startwith(string, search) and endwith(string, search), respectively, and return true or false if the target string begins or ends with that string.
# true
startswith("Hello, world", "Hello")
# false
startswith("Hello, world", "hello")
# true
endswith("Hello, world", "world")
Format String
sprintf
sprintf has the form of sprintf(format, values). It generates strings that reflect the format, similar to the sprintf in other languages, such as the C language. Since OPA's Rego does not support variadic arguements, values passed to sprintf must be placed in an array.
# "hex (c9) == decimal (201)\n"
sprintf("hex (%x) == decimal (%d)\n", [201,201])
format_int
format_int receives number and base to use, and returns a string that reflects the base of the numeric value. An example of using format_int is as follows.
# "b20"
format_int(2848,16)
# "11110"
format_int(30,2)
Case Conversion
The upper and lower functions allow for easy case conversion. upper and lower take over the string to be converted and return the string converted to uppercase and lowercase, respectively.
# "HELLO"
upper("Hello")
# "hello"
lower("Hello")
String Manipulation Functions
concat
concat has a concat (delimiter, array_or_set) format, and concatenate strings passed to an array or set into one using a specified separator. A delimiter is a string format as the first factor, and an array or set must contain only strings. Examples of uses include:
# "hello****world****!"
concat("****" , ["hello", "world", "!"])
# "apple.banana.pineapple"
concat("." , ["apple", "banana", "pineapple"])
split
split is the form of split (string, delimiter) and, as opposed to concat, splits the string by separator and returns the string array. Examples of uses include:
# ["hello", "world", "!"])
split("hello****world****!", "****")
# ["apple", "banana", "pineapple"]
split("apple.banana.pineapple", ".")
# ["apple.banana.pineaplle"]
split("apple.banana.pineaplle", " ")
substring
A substring has the form of a substring (string, start, length) and returns a string from which a portion is extracted. The starting position starts at zero, and an error occurs if it is negative. It returns a string of length from the start position, and a zero indicates an empty string, and if length of a negative means start from to end of the string.
# "1234"
substring("123456789", 0, 4)
# "4567"
substring("123456789", 3, 4)
# "456789"
substring("123456789", 3, -1)
# 1 error occurred: substring("123456789", -1, 4): eval_builtin_error: substring: negative offset
substring("123456789", -1, 4)
replace
replace takes the form of replace (string, old, new) and changes certain parts of a string to other content. Simply put, everything in the editor works like finding and replacing. Since they are all found and replaced, regular expressions should be used in situations such as changing only when first discovered. Examples of uses of replace include:
# "1X1X111XXX111111111"
replace("1010111000111111111","0","X")
# "applepie"
replace("applebanana","banana","pie")
strings.replace_n
strings.replace_n has the form of strings.replace_n (patterns, strings), and the difference with replace is that multiple strings can be replaced at once by creating a key and a value object. If multiple strings need to be replaced, it is more efficient than calling replace multiple times. Examples of uses of strings.replace_n include:
# "Pine_Apple“
strings.replace_n( {"pine":"Pine", "apple":"Apple"}, "pine_apple")
Trim String
trim_space
trim_space has the form of trim_space (string) and removes spaces at the front and back of the string (such as space characters, tab characters, open characters, and so on). Examples of uses include:
# "this is trim test"
trim_space(" this is trim test\n")
trim, trim_left and trim_right
trim, trim_left, trim_right has trim(string, cutset), trim_left(string, cutset), and trim_right(string, cutset) formats, respectively, eliminating characters belonging to strings handed to the cutset part. Trim is removed from both sides, trim_left and trim_right from the left. Because OPA does not have a character type and does not treat a string as an array of characters, the cutset argument that uses a string as a set of characters is a special case only in the trim function and requires attention. Examples of uses include:
# "Hello, world“
trim("Hello, world", ", ")
# "this is trim test"
trim(" this is trim test\n", "\n ")
# "this is trim test"
trim(".... this is trim test\n", ".\n ")
# "this is trim test“
trim(".... \nthis is trim test\n", ".\n ")
# "this is trim test\n“
trim_left(".... \nthis is trim test\n", ".\n ")
# ".... \nthis is trim test"
trim_right(".... \nthis is trim test\n", ".\n ")
trim_prefix, trim_suffix
trim_prefix and trim_suppix have the form trim_prefix(string, prefix) and trim_suppix(string, prefix), respectively, and remove the specified prefix or suffix (postfix). If the prefix or suffix pattern does not match, the original string is returned. Examples of uses include:
# "** message *****“
trim_prefix("***** message *****", "***")
# " message *****"
trim_prefix("***** message *****", "*****")
# "***** message *“
trim_suffix("***** message *****", "****")
Regular Expression Related Functions
Since the runtime of OPA is implemented in the Go language, the regular expression grammar used is the same as the regular expression used in the Go language, and for accurate grammar, see https://github.com/google/re2/wiki/Syntax. This book does not deal directly with regular expression grammar.
regex.is_valid
regex.is_valid checks if a string passed over to an argument fits the regular expression format supported by OPA. If the format is supported by OPA, it will return true and return false if it is not supported, but if the format cannot be recognized as regular expression at all, it will result in an illegal token error. Because OPA does not support all regular expression formats, if the regular expression does not behave as expected, it can be used to determine whether the regular expression itself is a supported format. However, since the regular expression format supported by OPA and the interpretation in some sense are different, you should check https://github.com/google/re2/wiki/Syntax if the format works differently even if it matches. Examples of use of regex.is_valid include:
# true
regex.is_valid("[[:alpha:]][[:alnum:]]+")
# 1:16: rego_parse_error: illegal token
regex.is_valid("\d+")
# true
regex.is_valid("\\d+")
# false
regex.is_valid("\\o+")
regex.match
regex.match has the form regex.match (pattern, value) and checks whether a particular string satisfies the corresponding regular expression pattern. For example, [:alpha:][:al num:]* is a regular expression that begins with an alphabet and can be followed by more than 0 arbitrary numbers or characters. If this expression is examined with regex.match, a1000000 and abcde are matched, but not 9ab0000 or 30000. Regex.match allows you to check whether the data entered is appropriate for the desired format. Examples of uses of regex.match include:
# true
regex.match("[[:alpha:]][[:alnum:]]*", "a100000")
# true
regex.match("[[:alpha:]][[:alnum:]]*", "abcde")
# false
regex.match("[[:alpha:]][[:alnum:]]*", "10000")
regex.split
regex.split returns the result of splitting a string into an array, using a regular expression pattern as a separator, rather than a simple string as a separator. Examples of uses of regex.split include:
# [ "", "12234", "9999" ]
regex.split("[\\*|\\+|\\-|x]+", "****12234xxxxx9999")
# [ "111", "111", "4444", "5555" ]
regex.split("[\\*|\\+|\\-|x]+", "111-111*4444x5555"
regex.globs_match
regex.globs_match compares two simple regular expressions at the Glob level to examine whether one is a relationship that is included in the other. For example, a+ matches "a", "aa", "aaa", ... with at least one a, but a matches empty strings and includes all that a+ matches such as "a", "aa", "aaa", ... . Relationships show that a+ is a subset of a. It returns true if these relationships are satisfied, and true even if they are identical (subset to each other). The OPA official document states that it only supports glob symbols such as .(dot), *, +, [, -, ], \, etc., and is only applicable to very simple forms of regular expressions. Examples of uses of regex.globs_match include:
# false
regex.globs_match("a+","ab")
# true
regex.globs_match("ab+","ab")
# true
regex.globs_match("ab+","ab*")
regex.template_match
regex.template_match has the form of regex.template_match (pattern, string, delimiter_start, delimiter_end), matching only the parts between the two arguments(delimiter_start, delimiter_end) as regular expressions, and matching the rest as regular strings. The entire matching can be expressed as a regular expression, but matching only between delimiters as a regular expression also increases readability, and the rest will be handled much more efficiently because simple string comparisons are performed. It is not allowed to use blank characters or :(colons) as delimiters, and it is safe to use parentheses. Examples of uses of regex.template_match include:
# true
regex.template_match("t-(10+)-235", "t-10000-235", "(", ")")
# false
regex.template_match("t-(10+)-235", "t-20000-235", "(", ")")
# true
regex.template_match("ast-[ab+]-235", "ast-abbbb-235", "[", "]")
# true
regex.template_match("ast-(ab+]-235", "ast-abbbb-235", "(", "]")
regex.find_n
regex.find_n has the form regex.find_n (pattern, string, number), returns the matching part of the regular expression by the number argument, and returns the entire number if the number is –1. Examples of uses of regex.find_n include:
# [ "abc", "bbb" ]
regex.find_n("[[:alpha:]]+", "123abc00bbb1111ccc", 2)
# [ "ABC", "CCC", "XX" ]
regex.find_n("[A-Z]+", "ABC0000abCCCabcXX222", 3)
regex.find_all_string_submatch_n
regex.find_all_string_submatch_n has the format regex.find_all_string_submatch_n(pattern, string, number) and returns a list of submatching including capture groups of regular expressions. The regular expression used in OPA is recognized as a capture group if the part of the regular expression is wrapped in ( ) and must be wrapped in (?: and ) for escape. Let's first look at an example to illustrate the capture group. Suppose you have a regular expression such as a(b)c(f)d, and call regex.find_all_string_submatch_n for each string "acd", "abcfffffd" that matches the regular expression. In the example, the number factor is set to –1 to match the whole.
# [ [ "acd", "", "" ] ]
regex.find_all_string_submatch_n("a(b*)c(f*)d", "acd", -1)
# [ [ "abcd", "b", "" ] ]
regex.find_all_string_submatch_n("a(b*)c(f*)d", "abcd", -1)
# [ [ "abbcfffffd", "bb", "fffff" ] ]
regex.find_all_string_submatch_n("a(b*)c(f*)d", "abbcfffffd", -1)
In the case of "acd", the first capture group (b) is matched to b is repeated more than 0 times and the second capture group (f) is also matched f* is matched to f is repeated more than 0 times. ["acd", "", "" ] was returned because the matching string was "acd" and two capture groups were matched to empty strings. In the case of "abcd", the matching string is "abcd" and the first capture group matched to "b", and the second capture group matched the empty string, so ["abcd", "b", ""] was returned. For "abbcfffffd", [abbcfffffd", "bb", "fffff"] was returned because “bb” were matched in the first capture group and “fffff” in the second capture group.
Let's escape the capture groups one by one and look at the results. As expected, we can confirm that the escaped part is not recognized as a capture group, and that the content about that part is excluded in the results.
# [ [ "abbcfffffd", "bb" ] ]
regex.find_all_string_submatch_n("a(b*)c(?:f*)d", "abbcfffffd", -1)
# [ [ "abcd", "" ] ]
regex.find_all_string_submatch_n("a(?:b*)c(f*)d", "abcd", -1)
If the strings to be matched are matched by multiple regular expressions, the matched strings and capture groups for each part are returned in an array.
# [ [ "acd", "", "" ], [ "abcd", "b", "" ], [ "abbcfffffd", "bb", "fffff" ] ]
regex.find_all_string_submatch_n("a(b*)c(f*)d", "acd__abcd0000abbcfffffd", 3)
Glob related Functions
Glob is a widely used pattern for file path matching and is a feature provided by almost any programming language. For example, use .jpg to refer to files with the extension jpg, or use ./**/.java to specify all java files in the subdirectory of the current directory.Using java is the glob pattern. Because organizations and permissions have hierarchical structures like files, glob can also be useful in implementing permissions and policies.
Glob Patterns
The Glob patterns used in Glob matching are shown in Table 4-4.
| Wildcard | Description | Example |
|---|---|---|
| ? | Match one character | ?at matches cat and bat, but not at |
| * | Match at least 0 characters | *kg matches both 1 kg and 10000 kg |
| ** | Match at least 0 characters across delimiter boundaries | */.rego matches both chap1/sample.rego book/source/chap1/sample.rego if separator is / |
| [abc] | Match one of the characters in [ ] | [bh]at matches bat and hat, but not cat |
| [a-z] | Match the range of characters in [ ] | [1-3]g matches 1g, 2g, 3g, etc., but does not match 6g |
| [!abc] | Any of the characters in [! ] do not match | [!c]at matches bat but cat doesn't match |
Table 4-4. Glob patterns used by OPA.
Glob Matching
It is important for OPA to match glob patterns with specific strings because comparisons to implement policies are the main purpose of the OPA. Functions to handle glob matching are provided in the form of glob.match (pattern, delayers, match). What is unusual is that the delimiters argument that specifies the separator is passed as an array, and if you pass [], "." is used. Examples of uses include:
# true
glob.match("?at", [], "bat")
# false
glob.match("[bh]at", [], "cat")
# true
glob.match("[!bh]at", [], "cat")
# false
glob.match("[1-4]kg", [], "6kg")
# false
glob.match("*.com", ["."], "test.example.com")
# true
glob.match("*.com", ["/"], "test.example.com")
# true
glob.match("**.com", ["."], "test.example.com")
# true
glob.match("**.com", [".","/"], "test/example.com")
#false
glob.match("*.com", [".","/"], "test/example.com")
Escaping
Although it is a string in the form of a glob pattern, there may be occasions when you want to treat the content as a string itself, not as a glob pattern. To this end, OPA provides a function for escape processing. The glob.quote_meta function has the form of glob.quote_meta(pattern) and returns an escaped string. Examples of uses include:
# "\\*.test.com"
glob.quote_meta("*.test.com")
# "\\*\\*/\\*.rego"
glob.quote_meta("**/*.rego")
HTTP related functions
http.send function has response := http.It has a send(request) format. Both request and response are objects and each has the required fields for HTTP requests and responses. An example of the use of http.send is as follows. The test used a popular public server, httpbin.org, for HTTP testing.
> http.send({"url":"http://httpbin.org/post", "method":"post", "timeout":"3s", "headers":{"token":"111"}, "body":{"key": "val"}})
{
"body": {
"args": {},
"data": "{\"key\":\"val\"}",
"files": {},
"form": {},
"headers": {
"Accept-Encoding": "gzip",
"Content-Length": "13",
"Host": "httpbin.org",
"Token": "111",
"User-Agent": "Open Policy Agent/0.35.0 (linux, amd64)",
"X-Amzn-Trace-Id": "Root=1-61cff125-334989227ad1766c0afef490"
},
"json": {
"key": "val"
},
"origin": "220.88.72.55",
"url": "http://httpbin.org/post"
},
"headers": {
"access-control-allow-credentials": [
"true"
],
"access-control-allow-origin": [
"*"
],
"content-length": [
"440"
],
"content-type": [
"application/json"
],
"date": [
"Sat, 01 Jan 2022 06:13:57 GMT"
],
"server": [
"gunicorn/19.9.0"
]
},
"raw_body": "{\n \"args\": {}, \n \"data\": \"{\\\"key\\\":\\\"val\\\"}\", \n \"files\": {}, \n \"form\": {}, \n \"headers\": {\n \"Accept-Encoding\": \"gzip\", \n \"Content-Length\": \"13\", \n \"Host\": \"httpbin.org\", \n \"Token\": \"111\", \n \"User-Agent\": \"Open Policy Agent/0.35.0 (linux, amd64)\", \n \"X-Amzn-Trace-Id\": \"Root=1-61cff125-334989227ad1766c0afef490\"\n }, \n \"json\": {\n \"key\": \"val\"\n }, \n \"origin\": \"220.88.72.55\", \n \"url\": \"http://httpbin.org/post\"\n}\n",
"status": "200 OK",
"status_code": 200
}
The required fields of the request object in http.send are url and method, and if the method is POST, the contents can be passed to the body field, and the headers field allows the HTTP header to pass tokens and so on for API calls. You can also use the timeout field to change the default timeout of 5 seconds. Since the result of http.send calls is returned to the object, assigning the result of http.send to a variable makes it easier to access the object's fields and process only the necessary information. For more information on the fields of request and response objects, see the official document (https://www.openpolicyagent.org/docs/latest/policy-reference/#http).
> response := http.send({"url":"http://httpbin.org/post", "method":"post", "timeout":"3s", "headers":{"token":"111"}, "body":{"key": "val"}})
Rule 'response' defined in package repl. Type 'show' to see rules.
> response.status_code
200
> response.body
{
"args": {},
"data": "{\"key\":\"val\"}",
"files": {},
"form": {},
"headers": {
"Accept-Encoding": "gzip",
"Content-Length": "13",
"Host": "httpbin.org",
"Token": "111",
"User-Agent": "Open Policy Agent/0.35.0 (linux, amd64)",
"X-Amzn-Trace-Id": "Root=1-61cff15a-17b45a6d2f3bbd71229a7a78"
},
"json": {
"key": "val"
},
"origin": "220.88.72.55",
"url": "http://httpbin.org/post"
}
JWT related functions
OPA provides built-in functions for JWT's signature, decoding, and verification. Since it is not often necessary to sign JWT within a policy, this book only introduces functions related to decoding and validation. Signing functions can also be useful when writing test codes, such as unit tests, so refer to official documents for interested readers. First, let's go to jwt.io and create a JWT for the test. As shown in Figure 4-2, the signature algorithm HS512, the header is {"alg": "HS512", "type": "JWT"}, the payload is {"sub":"1234567890", "name":"OPA Test", "iat": 1516239022}. Secret code is set to secret.
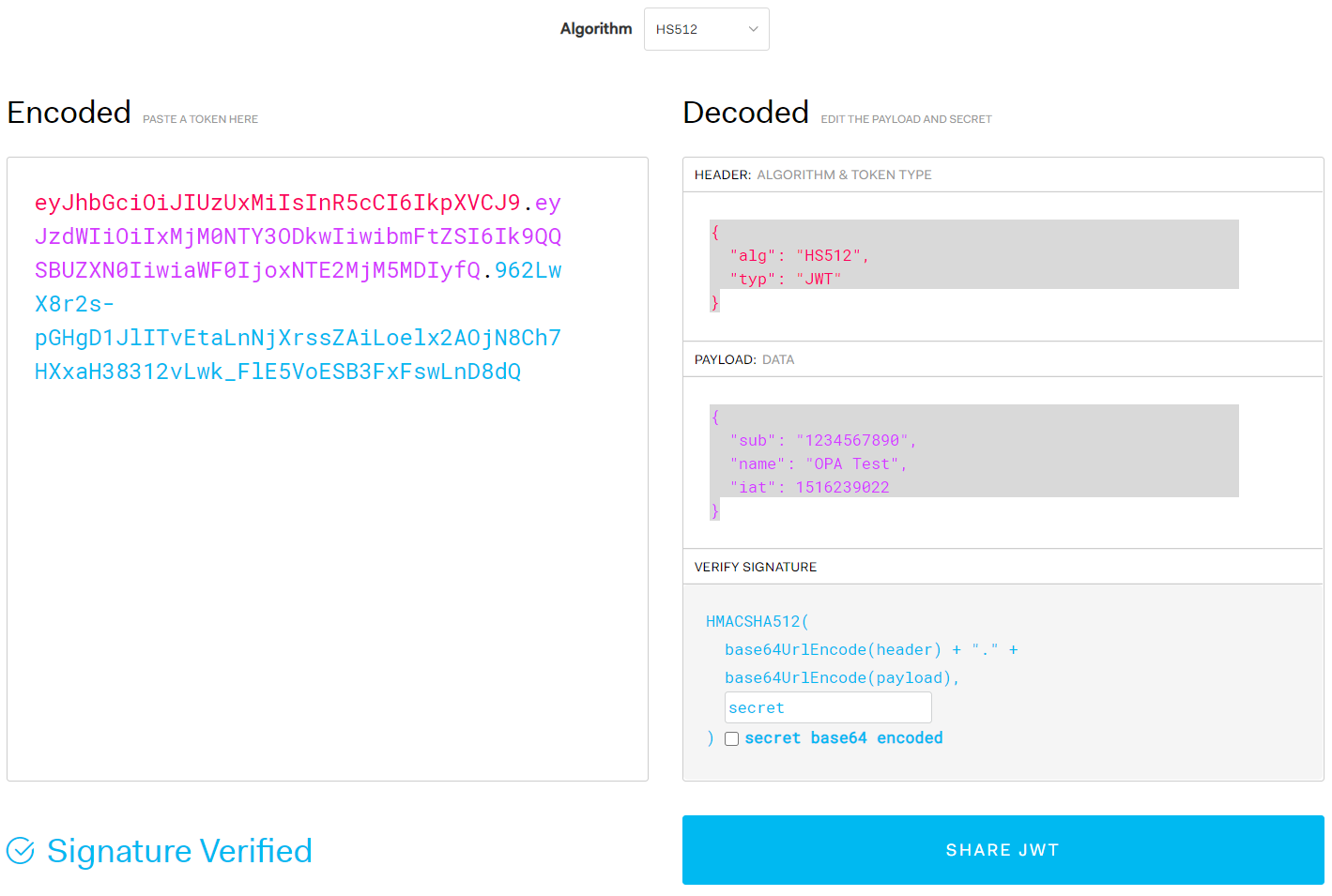
Figure 4-2. Creating a JWT for testing
The resulting code appears in the Encoded section in the following form.
eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6Ik9QQSBUZXN0IiwiaWF0IjoxNTE2MjM5MDIyfQ.962LwX8r2s-pGHgD1JlITvEtaLnNjXrssZAiLoelx2AOjN8Ch7HXxaH38312vLwk_FlE5VoESB3FxFswLnD8dQ
JWT Decoding Function
JWT can be decoded by calling io.jwt.decode(token). The token argument is in string format, and JWT itself is separated by a . and consists of header, payload and signature, each encoded in an enhanced Base64 encoding available for URLs. The JWT decoding function performs only decoding and does not validate the signature itself. For example, the io.jwt.decode result was returned as an array, with the first part being the header of the JWT and the second part being the payload, both of which being objects. The last is a string containing the signature part.
> io.jwt.decode("eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6Ik9QQSBUZXN0IiwiaWF0IjoxNTE2MjM5MDIyfQ.962LwX8r2s-pGHgD1JlITvEtaLnNjXrssZAiLoelx2AOjN8Ch7HXxaH38312vLwk_FlE5VoESB3FxFswLnD8dQ")
[
{
"alg": "HS512",
"typ": "JWT"
},
{
"iat": 1516239022,
"name": "OPA Test",
"sub": "1234567890"
},
"f7ad8bc17f2bdacfa9187803d499484ef12d68b9cd8d7aecb190222e87a5c7600e8cdf0287b1d7c5a1f7f37d76bcbc24fc5944e55a04481dc5c45b302e70fc75"
]
JWT Signature Verification
Functions validating JWT signatures have the form io.jwt.verify_
In the previous example, we validate the JWT generated by the HS512 algorithm, the secret code "secret", and the results are as follows.
> io.jwt.verify_hs512("eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6Ik9QQSBUZXN0IiwiaWF0IjoxNTE2MjM5MDIyfQ.962LwX8r2s-pGHgD1JlITvEtaLnNjXrssZAiLoelx2AOjN8Ch7HXxaH38312vLwk_FlE5VoESB3FxFswLnD8dQ", "secret")
true
OPA provides an io.jwt.decode_verify function that simultaneously handles decoding and validation of tokens. io.jwt.decode_verify has the form of io.jwt.decode_verify(string, constraints) and argument constraints is an object. Examples of uses of the function io.jwt.decode_verify are as follows. The results confirm the success of the verification and the return of the decoded headers and payloads.
> io.jwt.decode_verify("eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6Ik9QQSBUZXN0IiwiaWF0IjoxNTE2MjM5MDIyfQ.962LwX8r2s-pGHgD1JlITvEtaLnNjXrssZAiLoelx2AOjN8Ch7HXxaH38312vLwk_FlE5VoESB3FxFswLnD8dQ", {"alg":"HS512","secret":"secret"})
[
true,
{
"alg": "HS512",
"typ": "JWT"
},
{
"iat": 1516239022,
"name": "OPA Test",
"sub": "1234567890"
}
]
Constraints of the function io.jwt.decode_verify can also be checked at a time by selectively passing the validity of JWT's issuer (iss field), exp field (exp field indicating the time of extinction, and nbf field indicating the effective start time), and JWT's specified audience(aud field). Using these features will reduce the code that rechecks on the decoded token. For more information, see the official document (https://www.openpolicyagent.org/docs/latest/policy-reference/#token-verification).
Summary
This chapter focuses on the various built-in functions provided by OPA that can be useful in policy writing. Built-in functions allow a variety of operations, such as extracting values from objects and transforming values, to compare policies beyond simple comparisons using the median operator. Complex pattern matching such as regular expressions and globs can also be performed.
In the next chapter, we use the Rego grammar described in the previous chapter and the built-in functions described in this chapter to write policies that could be used in the actual development process.